
Announcing Agentic Property Extraction: Extracting structured data fields from unstructured documents
December 4, 2025
Introduction
Modern enterprises run on documents — contracts, invoices, forms, submissions, policies — each carrying hundreds of latent properties that drive workflows and ultimately business decisions. Yet, these documents arrive in wildly inconsistent formats, layouts, and vocabularies, making reliable extraction one of the hardest automation problems in the enterprise stack. We work with insurance, legal, and logistics companies many of whom had no choice but to process their documents manually.
So, we reframed the problem. Instead of fixed OCR pipelines that break when documents don’t fit a pattern, can we take an agentic approach that adapts the processing to the document? Leaning into our database roots, we chose a declarative interface. Provide us a schema or use one that we suggest, and Aryn will automatically fill in the schema no matter the size or shape of the document.
We call this capability Agentic Property Extraction, and we’re releasing it today for you to enjoy. Whether parsing a restaurant menu into dish-level attributes, converting an invoice into a normalized itemization, or turning messy insurance loss runs into a standardized, actuarial-ready schema, agentic property extraction adapts dynamically to the document—not the other way around.
The result is structured data with a consistent schema across unstructured heterogeneous documents. We not only handle atomic properties such as dates, amounts, or descriptions, but we also handle deeply nested data with repeated fields such as claims and loss details. By converting to structured data, enterprises can then leverage the plethora of tools already at their disposal, such as spreadsheets, databases, and data warehouses for downstream tasks. For example, you can use it to accelerate policy quoting workflows for underwriters or accelerate claims processing for adjustors.
Let’s see it in action!
Geting started with DocParse
We’re going to walk you through a simple example of property extraction from documents as diverse as restaurant menus and worker’s compensation (WC) loss runs or claims history typically used for underwriting.
We’ll be using the Aryn DocParse UI, so go ahead and get setup with console access and an API key for free. Download the sample WC loss runs and restaurant menu files.
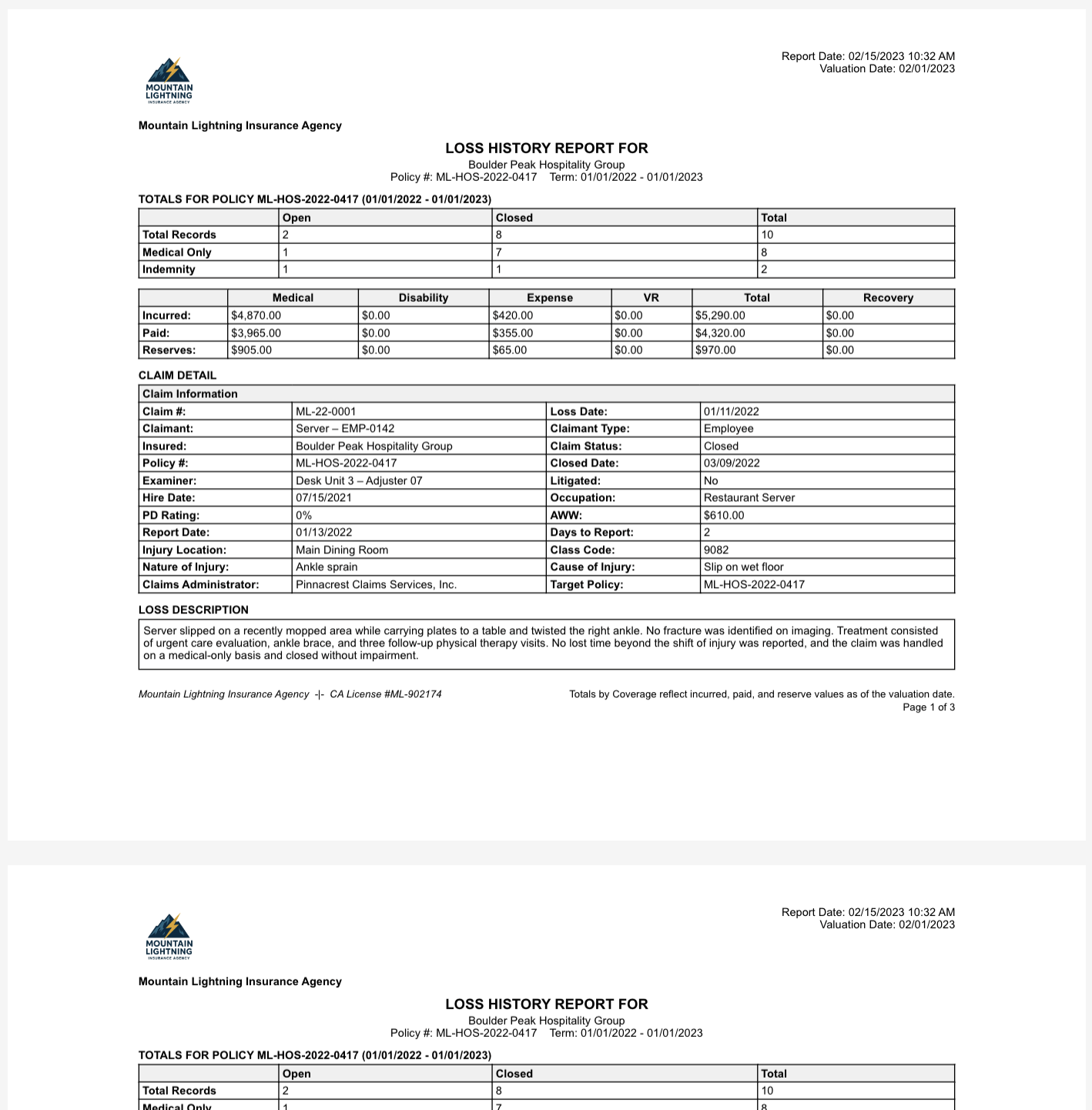

These documents have wildly differing layouts and content from other documents of the same category as well as from one another. Our agentic property extraction works in both situations.
Next go to DocParse Playground and upload the file. You’ll see options for parsing the document and configuring a schema. The defaults for parsing work pretty well, and you can choose vision OCR for text mode and vision for table mode to trade off speed for quality.
DocParse automatically suggests schemas
Next you’ll want to Configure Schema to tell DocParse what schema to extract, if any.
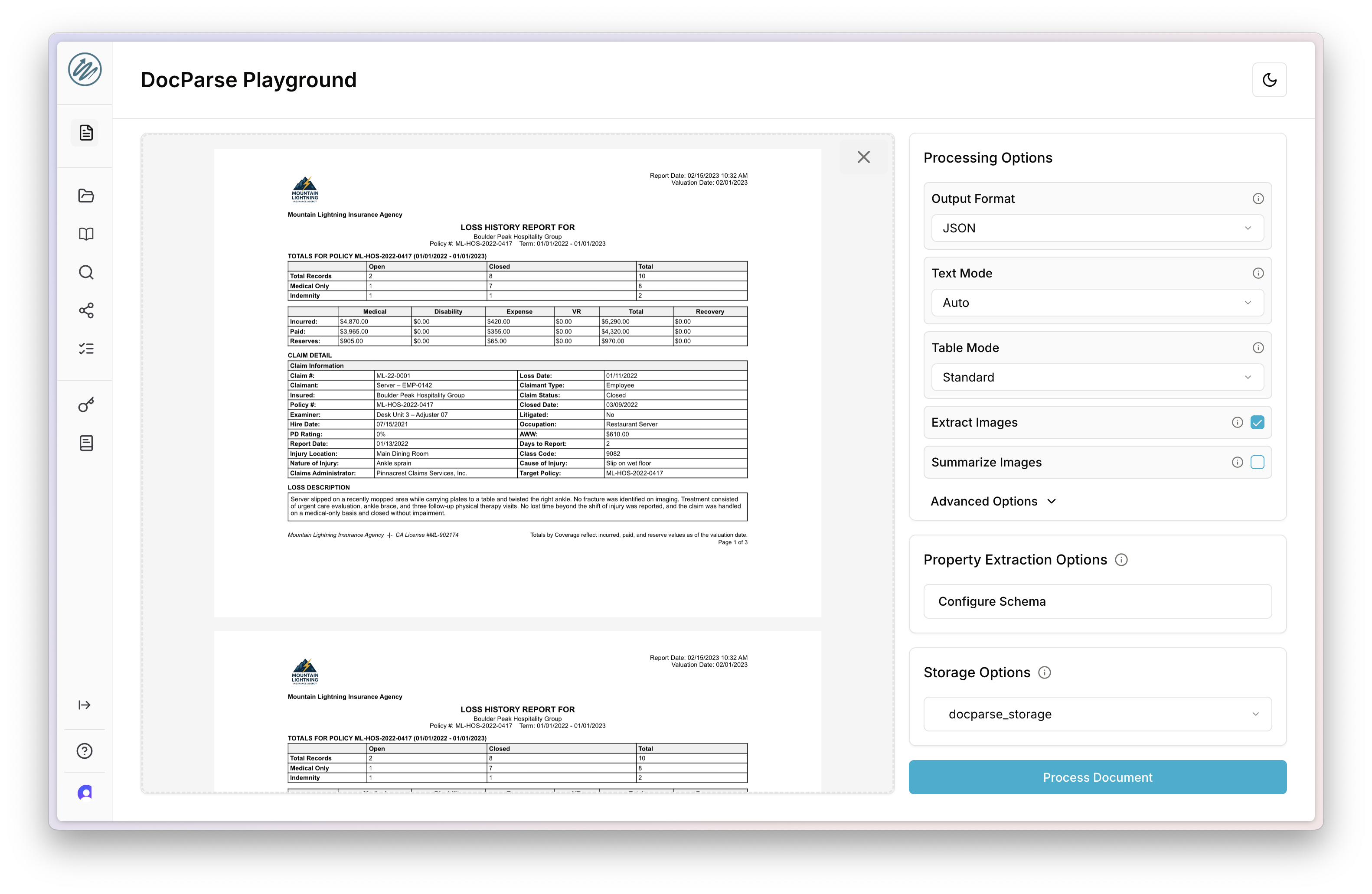
You can provide your own schema or ask DocParse to suggest one for you. Under the hood, it automatically parses and does clever context engineering with frontier models to generate and propose quality schemas. You don’t have to worry about the size or complexity of the document.

You’ll see it recommends atomic properties (agency_name), nested objects (policy_term), and repeated nested objects (claims). It automatically provides field names, types, and descriptions of the fields based on what it sees from the documents. You can browse the properties and their descriptions on the right and edit the schema and properties as you wish. Our tutorial shows you how to edit the schema via the DocParse UI.
Click Save Schema and when it returns to the Playground, click Process Document. You’ll see Aryn parse the document and extract properties using agentic techniques.
Property extraction provides element-level attributions
You can browse the enumerated results on the right, and click on the attributions (e.g. Element Y tags) to see which element in the document the properties came from. Here are the results for the WC loss runs and restaurant menu examples:
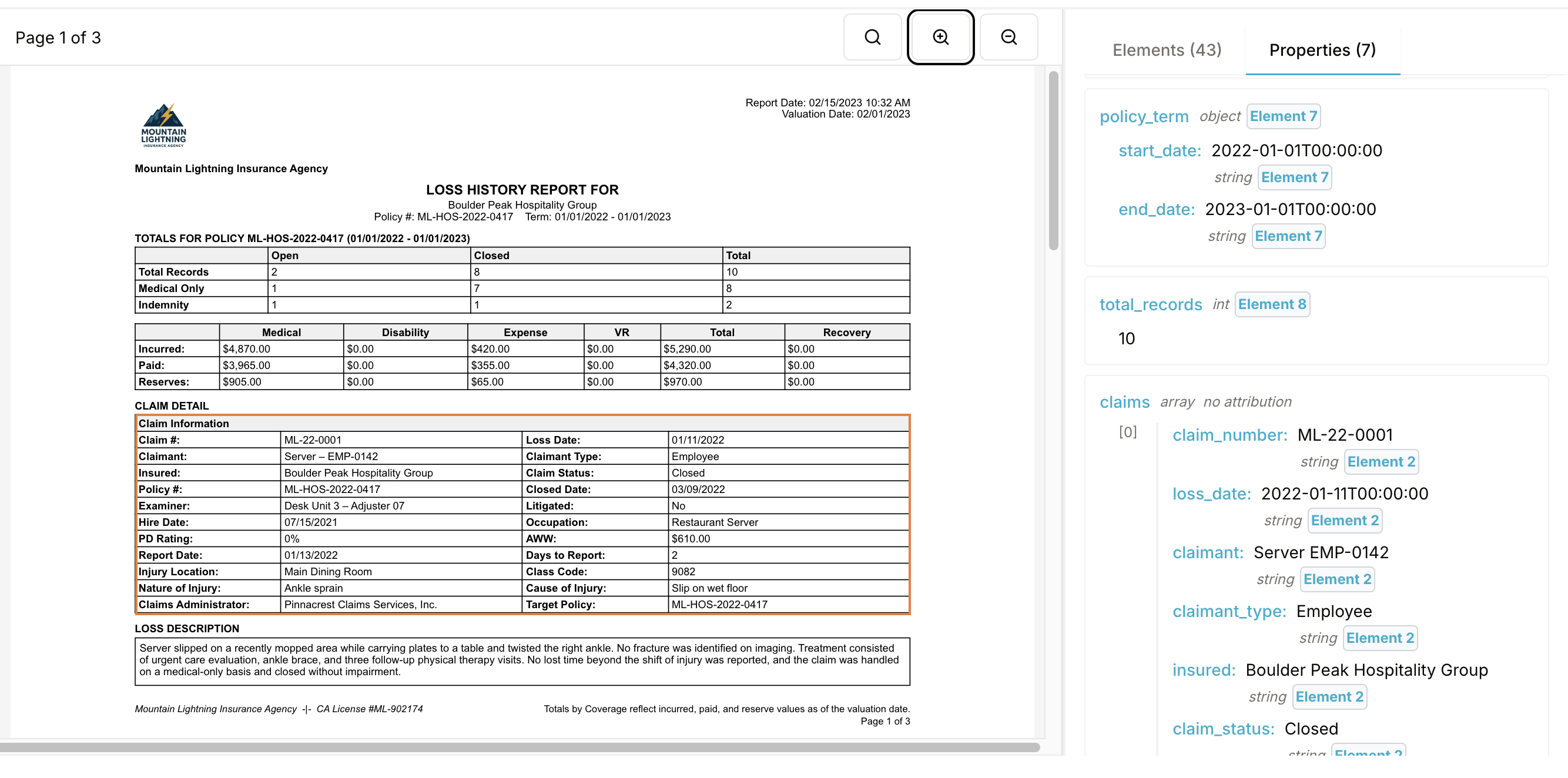
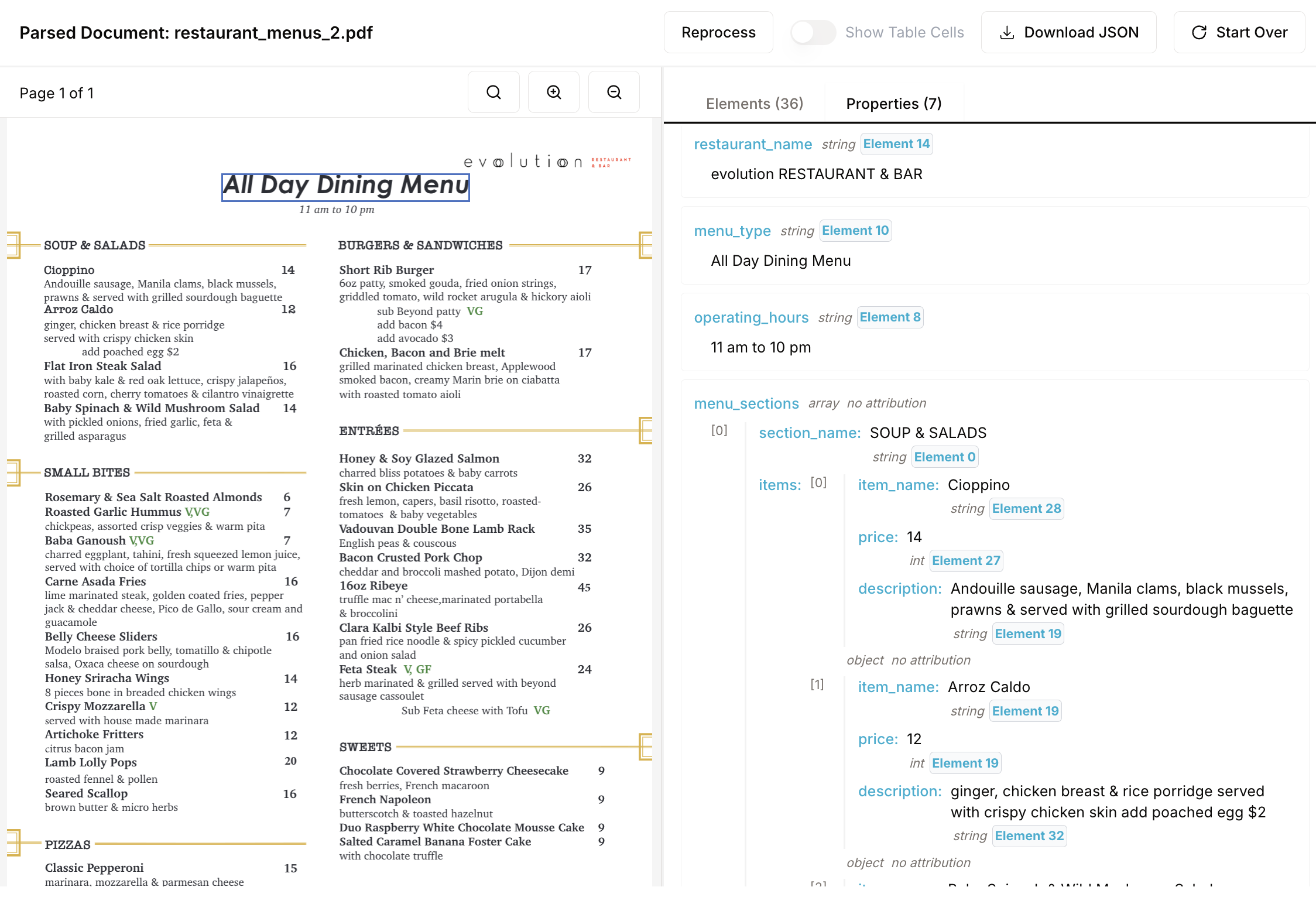
Agentic property extraction and its features are not only available in the UI but also via API. The tutorials and API documentation show you how you can use it programmatically with the Aryn SDK. This will allow you to scale it across thousands and thousands of documents, and we’ve seen it attain accuracy above 95%.
Build your document pipelines with DocParse today
Agentic Property Extraction is a powerful new feature that can extract high quality structured data from unstructured documents of all types such as menus, invoices, and insurance documents. Leveraging the capabilities of frontier models and visual AI, it is robust to variations in layout, terminology, and formats. With Aryn DocParse, you can build agentic property extraction into your own document pipelines and get high quality results at scale.
Check it out yourself. It's free to try out. Let us know what you think on the Aryn Community Slack.