Aryn has been acquired by Glean! Together we are building the future of enterprise knowledge and document intelligence.

Unleash the power of AI to structure your unstructured data with accuracy at scale
Highly accurate parsing using vision AI models and an agentic data processing engine.
Parse documents with tables, images, and different languages with >95% accuracy
Handle 33+ different document types
JSON, HTML, or Markdown outputs
Scale to millions of documents
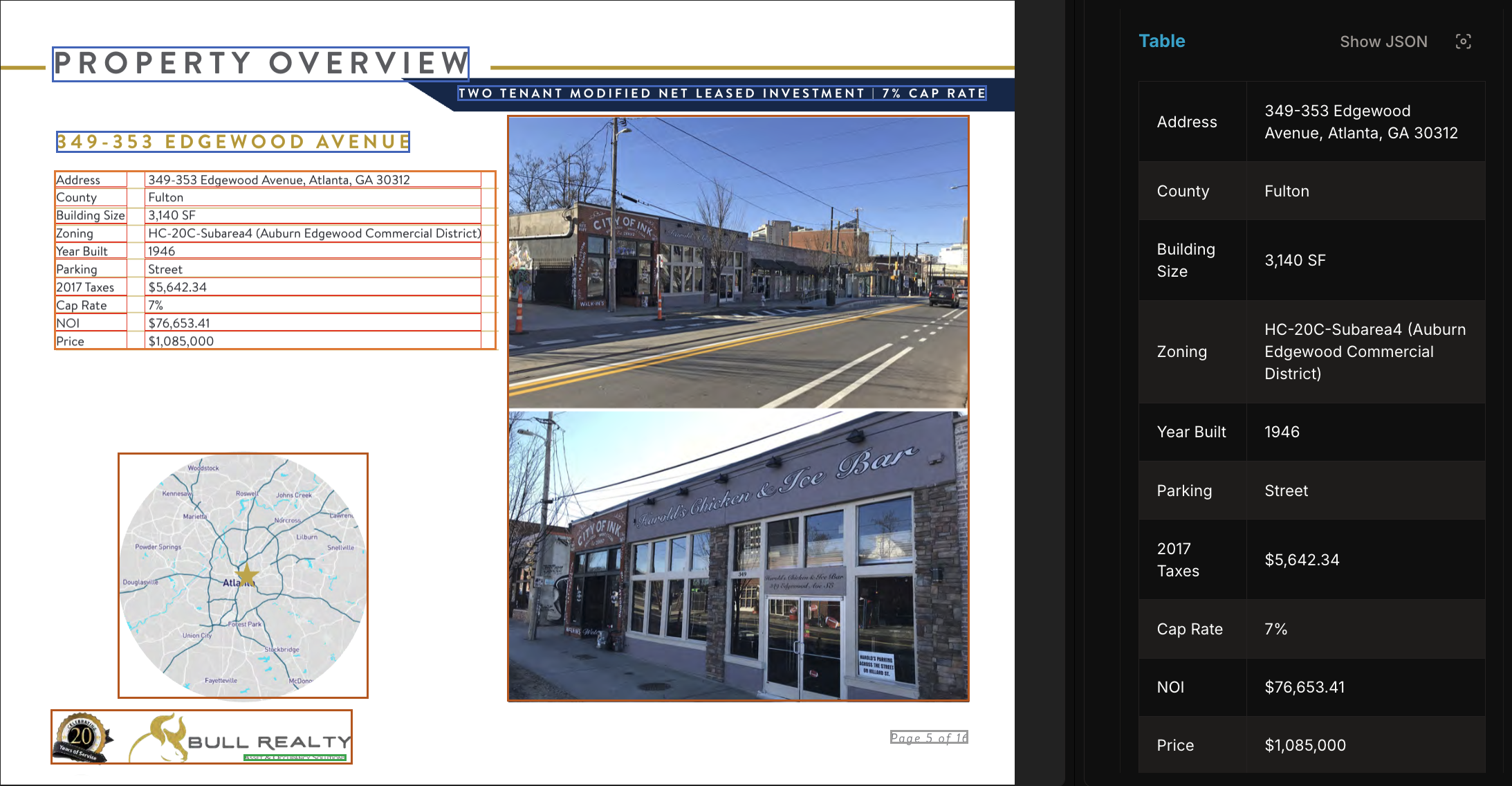
Intelligent property extraction using customized AI models
Uses state-of-the-art VLMs and custom vision models
Supports nested fields, repeated values, and element level attribution
>98% accuracy on real world use cases
Scales to millions of documents
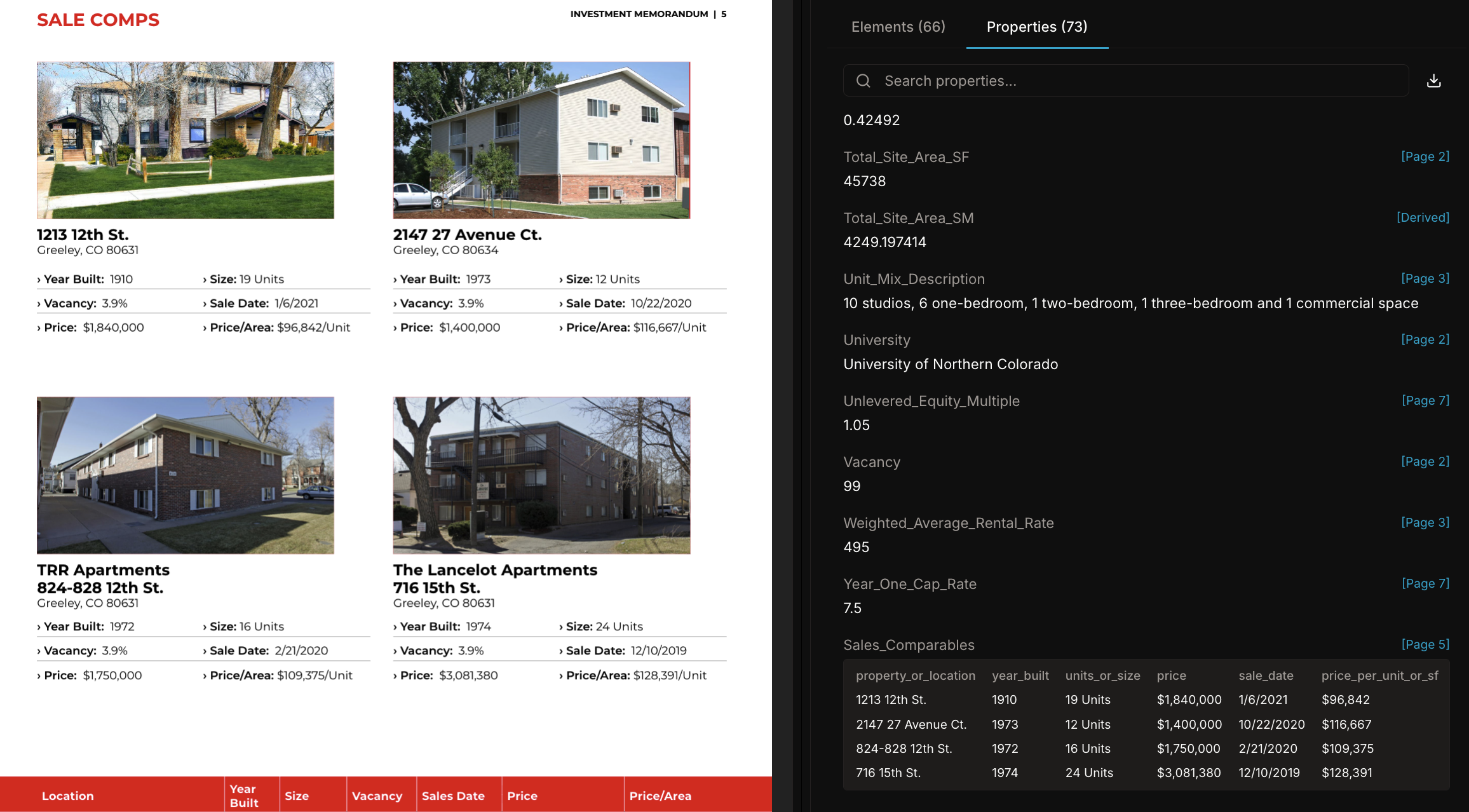
Advanced parsing and property extraction tailored for enterprise document processing.
Eliminate tedious and error-prone heavy-lifting for critical document workflows
Insurance MGAs: 10x faster turnaround times for underwriting sales and policy premium quoting workflows
BPOs: Process claims faster and with higher accuracy
Logistics: Accelerate turnaround time for RFPs


Run your document automation pipelines securely in Aryn’s cloud, or deploy Aryn containers in your self-managed environments
Aryn Cloud
Run on-demand with Aryn’s Cloud UI or API. SOC2 Type 2 and ISO 270001 compliance
Your Environment
Deploy 0-CVE Aryn containers in your VPC, on-premises, and air-gapped environments

"At SUI (Novacore), AI is fundamentally transforming our underwriting operation. Given the scale and complexity of our book, the variety of risks we cover, and our aggressive turnaround requirements, manual data extraction and entry had become a major bottleneck for our underwriters.
With Aryn’s agentic document pipelines, we’ve completely eliminated the tedious, error-prone manual process from submission intake to quote. Tasks that once took hours or even days are now completed in minutes with greater than 98% accuracy—without forcing us to change our existing workflows.
This has freed our underwriters to focus on higher-value risk analysis and client advisory work, dramatically boosted overall productivity, and enabled us to respond to brokers and clients far faster than ever before. The result is directly driving higher submission-to-quote ratios, materially increasing the number of policies we bind, and delivering substantial top-line growth for Strategic Underwriters International and the entire Novacore platform."
"Most agentic workflows stall or break when documents are messy and inconsistent. In enterprises, unstructured data is the bottleneck. Aryn, now integrated in DataRobot's Agent Workforce Platform, lets agents turn messy documents into structured fields reliably and at scale. With Aryn, DataRobot customers can now build accurate and reliable agents without having to write custom parsing code. This not only speeds up time to production by 10x, but also makes those agents more trustworthy."
- Bill Reichert, President - Strategic Underwriters International (SUI),
a division of Novacore
- Prajakta Damle, SVP Product, DataRobot
Accuracy across millions of documents
Lower cost for parsing and field extraction vs. hyperscalers
Agentic Document Intelligence.